
This week was about general-purpose lossless data compression methods. The idea here is as follows. Let's say we have a file which only has 4 different characters in it: A, G, C, T. The file describes the DNA composition of a human and contains nucleic acid sequences. A simple way to code (w/o compression) the 4 characters would be to use 2 bits for each of them. For ex. A=00, G=01, C=10, T=11. However, if some characters occur more frequently than the others, we can code the most frequently occuring character with 1 bit and make the resulting file smaller. The motivation behind Morse Code (for telegraphy) is pretty much the same. Looking at the Morse Code alphabet one can tell the most frequently used characters in English. Please note that Morse code is not a prefix-free code unlike Huffman codes. See also here for a list of Morse codes.
The above statement was basically what Huffman observed when he was doing his PhD thesis at MIT. Huffman finished his PhD at MIT in 1953 and stayed there as an assistant professor and joined University of California, Santa Cruz in 1967 (my wife's university) and stayed there until his death in 1999.
Exercise: We have 3 different characters in a file of
1 million characters: a, b, c. No compression but a little smarts
tells us we can code each character with 2 bits. This gives us a file
size of 250kB. However, if the probabilities (occurence rate) of the
three characters are not equal, we may be able to save space. Let's
say a has a probability of 50% whereas b and c
are 25% each. If we code a with 0, and b and c with 10 and 11, we save
500 thousand bits (ie. 62.5kB) and reduce the file size by 25%. Here,
0 indicates the character is a. If we are at the first bit of a
character and the bit is 1, then it is either b or c. If the second
bit is 0, it is b otherwise c. So what we do is variable length
coding. That is, each character may have a different number of
characters. So to decipher characters, we do not do a simple table
look-up operation as in fixed length coding. Instead, it is a decision
tree based process.
One may ask the following legitimate question. How does the decoder (which may be kms apart from the encoder) know how the encoder decided to code the characters? There are two answers to this. Either both sides use identical adaptive algorithms to determine the probabilities. They start at equal probabilities. This is called Adaptive Huffman Coding. This is beyond our topic in this course. The other alternative is for the encoder to send "header info" and code the coding of the characters. This is the alternative we talked about in this lecture. This technique requires the encoder to process the input file twice. First time to come up with the occurence rate of the characters and to code them and the second the second time to code the entire file. There is also the question of how to signal the "end of file" (EOF). One way is to append the file length to the header. The other technique is to invent an EOF character with a low occurence rate and to code it as well. In the first technique, the decoder counts the number of characters and when it sees that it has received the number of characters it was supposed to receive, it stops the decode process. In the second technique, the decoder keeps decoding until it decodes and EOF character. Note that the header uses a fixed format coding that both sides know and there are efficient ways to code the header which we will not go into here.
We derived a systematic way (ie. algorithm) to come up with the
Huffman codes of characters given their probabilities
1. Sort the characters with respect to (wrt) their probabilities, the lowest one being first.
2. In the case of a tie, put the character in their alphabetic order.
3. In the case of a tie, put the character in their alphabetic order.
4. Take the two lowest prob. characters.
5. Combine them in a binary tree node. Put the left one in the sorted list on the left and the right one on the right. Write 0 on the left edge and 1 on the right edge.
6. Add up the probabilities of the two characters, assign it to the newly created node. Insert the node into the sorted list at the corect position.
7. Take the two lowest prob. character/node. Go to 5. Repeat until there is only one node.
Exercise: We applied the above algorithm to an
example in the class. See below.
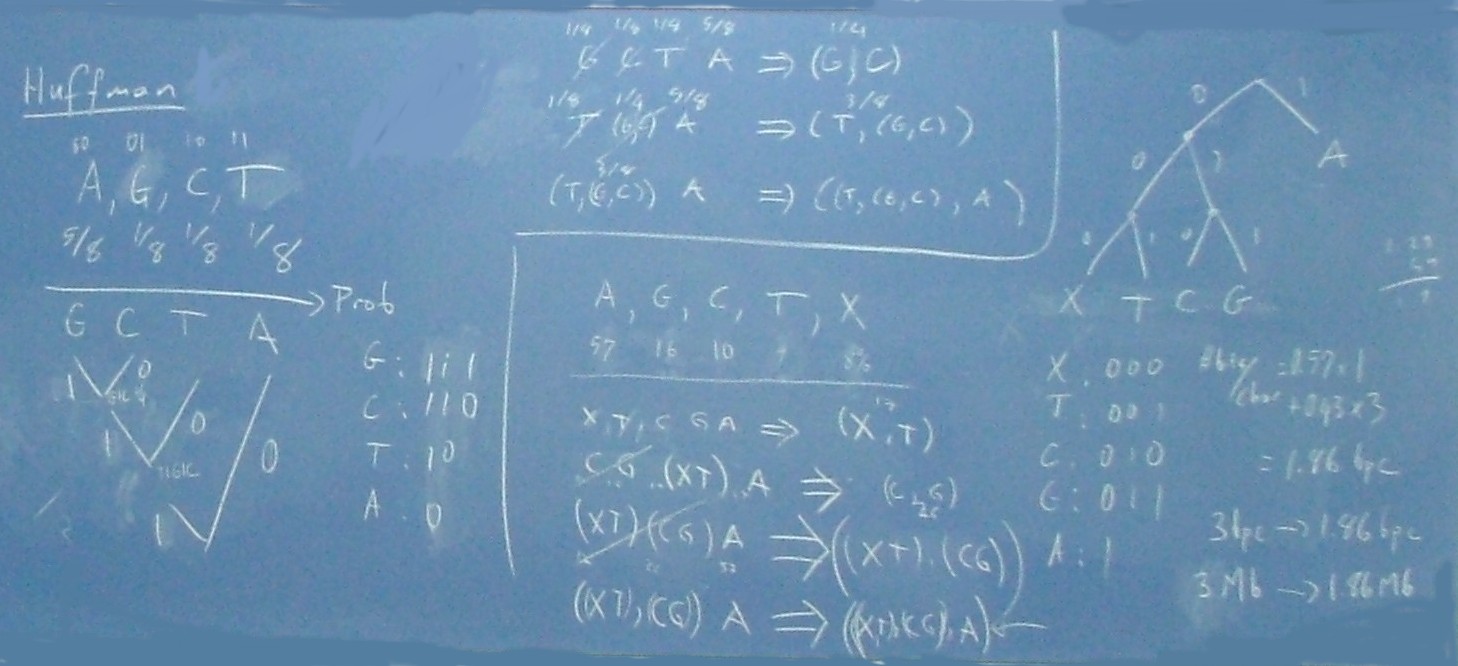
Modern file compression software are based on variants of LZ compression. LZ compression is really not a compression technique. It uses Huffman coding for compression. What LZ does is it finds repeating patterns (ie. sequences of characters) using a dictionary-based method and treats them as a single character by assigning them a code. Effectively, LZ switches the alphabet to a more efficient alphabet. It is the same idea what is behind stenography (ie. short-hand that court clerks use on their special typewriters). After an LZ step, compression software such as zip, gzip apply Huffman coding to the new alphabet. When Huffman coding is used, LZ is especially useful. This is because Huffman coding asigns an integer number of bits to each character no matter what the exact occurence frequency is. By grouping characters into a single symbol, LZ helps Huffman coding get near the Shannon limit (or entrophy). Arithmetic coding, however, does not have the problem Huffman coding has. See this page for an LZ exercise (as well as a Huffman exercise).
We used the following algorithm for LZ:
1. Add all the characters to the dictionary.
2. Set max_n=1.
3. Initialize your pointer so that it points to the first char in the file.
4. Set n=max_n.
5. Take an n-long sequence and match it to the dictionary.
6. If there is no match, decrement n until there is a match.
7. Add the n+1 long sequence to the dictionary.
8. Update max_n.
9. Replace the matching sequence with the address of the sequence in the dictionary.
10. Move the pointer to the char which caused the last mismatch.
Exercise: We applied the above algorithm to an
example in the class. See below.
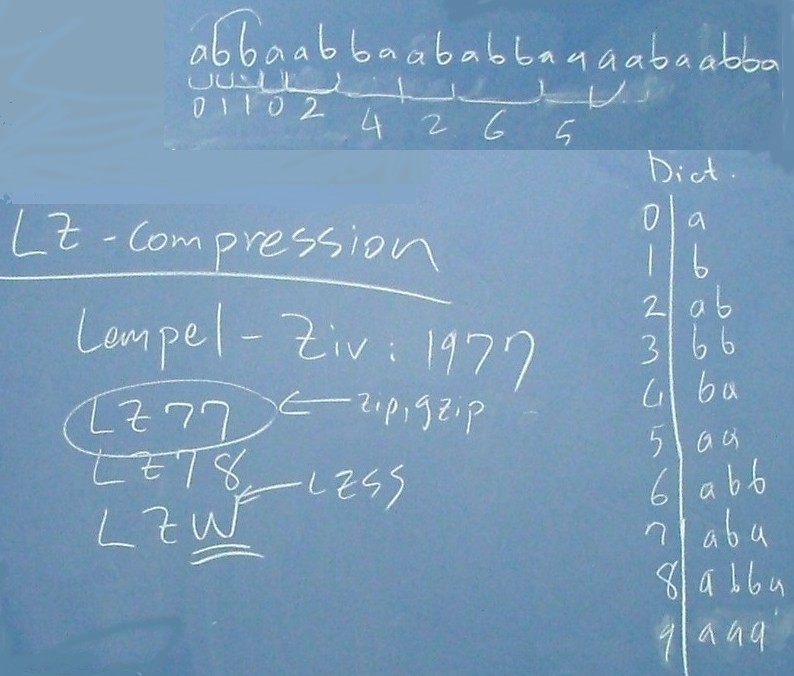
The Shannon Limit states a lower bound on the average "bits per char" (bpc) given the char probabilities. It is also called the Shannon Entrophy. Shannon says no matter what compression method you use, the average bpc you achieve cannot be lower than Shannon Entrophy of a file. You can see the formula in the above link or here.
Shannon is not only known as the father of Information Theory but he has other works which sit at the border of Information Theory and Signal Processing. Scroll down when you follow the link to Wikipedia. See the "See Also" section. We discused "Nyquist-Shannon sampling theorem" last week. "Shannon capacity" is yet another work by Shannon. It states the max possible "bits per second" one can achieve on a given communications channel given the Signal-to-Noise ratio of the channel. For quite sometime, 33.6kbps was thought to be the max rate one can achieve on residential phone lines with the use of analog modems. This limit was derived thru Shannon's Capacity Theorem. When US Robotics and Lucent Technologies independently invented the first 56kbps analog modem around 1993, everybody initially thought it was not only a breakthrough but also a violation Shannon's Capacity Theorem. However, a close look at it shows there is no theory violation. 56kbps modems require digital modems on the ISP side and that changes S/N numbers. However, that was till a breakthrough.
The person behind the Lucent invention was Dr. Nuri Dagdeviren. This invention got Nuri a Bell Labs Fellow honor. Bell Labs is the place where many fundamentals discoveries and inventions were made such as the invention of the transistor. Bell LAbs has many Nobel prize winners. And Bell LAbs Fellow award is considered Bell Labs internal Nobel prize. Bell Labs is the research arm of Lucent Technologies and formerly ATT. I also worked at Lucent between 1997-2001 and I was considered a Bell Labs employee for a brief period until we git restructured. Nuri was a legendary student at Bogazici University. He has finished the Physics Dept. in 3 years and then went to MIT and finished his Physics PhD in 3 years. Then did a postdoc at CalTech for a few years. Joined Bell Labs later on. He was initially doing research in Physics but later on switched to Signal Processing. He later on became a director of DSL chips. He then worked on WiFi chips at European locations of Lucent. He is currently the VP&General Manager of Samsung Business Group at Agere Systems (formerly a division of Lucent).
Reading materials:
See the pictures of the board in our lectures.
Other compression sources: ref1, ref2, ref3, ref4,
ref5.
{kind=link}